ブルームバーグは、新たな大規模生成型人工知能(AI)モデルである「BloombergGPTTM」の開発に関する研究論文を公開しました。
この大規模言語モデル(LLM)は、金融データの多岐にわたる領域に特化した訓練を受け、金融業界内での多様な自然言語処理(NLP)タスクを強力にサポートします。
最近の人工知能(AI)の進歩により、LLMをベースにした新たな応用がさまざまな分野で展開されています。
しかし、金融分野は複雑さと独自の専門用語を持つため、特有のモデルが必要とされます。BloombergGPTは、金融業界におけるこの新技術の開発と適用の初めの一歩を示しています。このモデルは、感情分析、固有名詞認識、ニュース分類、質問応答などの既存の金融NLPタスクを向上させるだけでなく、ブルームバーグ・ターミナルに蓄積された膨大なデータを活用し、金融分野におけるAIの可能性を最大限に引き出します。
そこで今回は、BloombergGPTの可能性について模索していきます!

- 取り扱い通貨数が豊富
- 取引画面の見やすさ・使いやすさ
- アプリダウンロード数、国内No.1.
- 口座開設や取引操作が簡単でスピーディー
- 取引所のビットコイン取引手数料が無料
- 運営の信頼性
- 安全なセキュリティ対策
- ビットコイン現物取引高2ヶ月連続「国内No.1」を獲得
\ 国内最大級の暗号資産取引所 /
BloombergGPT
ブルームバーグは10年以上にわたり、AI、機械学習、NLPを金融分野に応用するパイオニアとしての地位を築いてきました。現在、ブルームバーグは幅広いNLPタスクをサポートしており、金融分野に特化した新しい言語モデルの導入によって更なる進化を遂げる見通しです。ブルームバーグの研究者は、金融データと一般的なデータを組み合わせてモデルを訓練する混合アプローチを開発し、金融のベンチマークで最高の結果を実現しつつ、一般的なLLMのベンチマークでも競争力のあるパフォーマンスを維持しました。
この目標を達成するため、ブルームバーグのMLプロダクトおよびリサーチ部門は、同社が長年蓄積してきたデータ作成、収集、キュレーションのリソースを活用し、前例のないドメイン固有のデータセットを構築しました。金融データ企業として、ブルームバーグのデータアナリストは40年以上にわたり金融文書の収集と保守に従事してきました。この幅広い金融データアーカイブをベースに、英語の金融文書からなる包括的な3630億トークンのデータセットが作成されました。
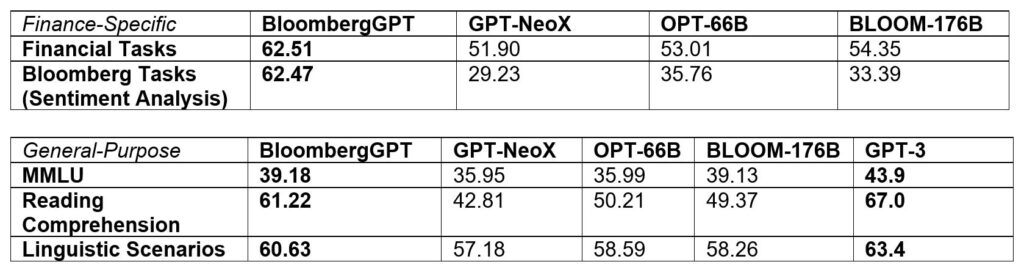
このデータに3450億トークンの公開データセットを組み合わせて、7000億トークンを超える大規模な訓練用データが構築されました。チームはこの訓練データの一部を使用して、5000億パラメータのデコーダーオンリーの因果言語モデルを訓練しました。その結果得られたモデルは、金融特有のNLPベンチマーク、ブルームバーグ内部ベンチマーク、一般的なNLPベンチマーク(BIG-bench Hard、Knowledge Assessments、Reading Comprehension、Linguistic Tasksなど)で評価されました。特筆すべきは、BloombergGPTモデルが同様の規模のオープンモデルに比べて金融タスクで大幅な優位性を発揮し、一般的なNLPベンチマークでも同等またはそれ以上の高いパフォーマンスを維持している点です。
ブルームバーグの最高技術責任者であるショーン・エドワーズは、「ジェネレーティブLLMの魅力的な側面 – フューショット学習、テキスト生成、会話システムなど – これらすべての理由において、金融領域に焦点を当てた初のLLMの開発には、非常に価値があると考えています」と述べました。「BloombergGPTは、新しい種類のアプリケーションに取り組むことを可能にし、カスタムモデルに比べてはるかに高い性能を提供し、さらにはより速いタイムトゥマーケットを実現します。」
また、ブルームバーグのMLプロダクトおよびリサーチチームのヘッドであるギデオン・マンは、「機械学習とNLPモデルの品質は、それに与えるデータにかかっています」と説明しました。「ブルームバーグが40年以上にわたってキュレーションしてきた金融文書の収集のおかげで、金融ユースケースに最適なLLMを訓練するための大規模でクリーンなドメイン固有のデータセットを慎重に作成することができました。私たちはBloombergGPTを使用して既存のNLPワークフローを改善するだけでなく、このモデルを顧客に喜んでいただくための新しい活用方法を考えることにワクワクしています。」
さらに、BloombergGPTの開発の詳細については、arXivでの論文をご覧いただくことをおすすめします。詳細はこちら:https://arxiv.org/abs/2303.17564。

- お得なキャンペーンを多数開催
- 各種手数料が無料
- ニッチ〜メジャーまで幅広い仮想通貨ラインナップ
- SBIグループの運営で安心感◎









