AIデータセンターの話題は、だいたいGPU枚数やラック密度で盛り上がります。しかし投資家として一番大事なのは、そこではありません。日本国内でどれだけのAIデータセンターが動けるのかを決めるのは、結局「IT供給電力(MW)」だからです。
いま国内では、AI対応データセンターのIT供給電力が2026年末に約600MWへ倍増する見通しが語られています。
数字だけ見れば景気がいい。しかし倍増は、建物を建てれば終わりではありません。用地、工期、系統接続、特高受電、変圧器、UPS、冷却、そして効率規律(PUE)、このどこかが詰まれば、MWは増えません。逆に言えば、詰まりどころが見えた瞬間に、どの領域に金が落ち、どの銘柄が恩恵を受けるかが逆算できます。
本稿では、まず議論の単位を「ラック」や「GPU」から切り離し、MW(IT供給電力)で現実を固定。そのうえで、国内AIデータセンター増設を工程分解し、どこが詰まるのか/詰まったときに誰が儲かるのかを、可能な限りデータで可視化していきます。
さらに、パワー半導体(SiC/GaN)や次世代メモリ周辺(HBMの次に語られがちなHBF)も、DCのボトルネック投資という軸で整理し直します。たとえば、ローム(6963)がNVIDIAと協業している「800V DC電源アーキテクチャ」は、材料で終わる話ではなく、MW競争のルールそのものを変えうる論点です。
なぜMWが増えないのか
国内のAIデータセンター(AI対応を明言する拠点)のIT供給電力は、2025年末約300MWから、2026年末約600MW、2027年末約800MWへ増える見通しです。
ただし、この「倍増」は建物を建てれば達成できる話ではありません。長期トレンドとしては増える前提でも、道中はスムーズに増えないことが多い、という意味です。実現MWが計画より遅れて積み上がる局面では、ほぼ例外なく建物の外側か電力の入口が詰まります。
データセンター建設は「建物が完成=即MW稼働」ではなく、受電(系統接続)・変電設備・冷却など入口側が条件になります。これらが遅れると、計画上のMW(planned)と実現MW(realized)がズレます。
ここを分解すると、投資家が見るべき点は大きく3つに整理できます。
ボトルネック①:系統接続(特高受電)
最初の詰まりは、電気を引き込む入口(受電点)です。
AI DCは高負荷なので、特別高圧での受電や、それに準じる大きな受電枠が必要になります。受電枠の確保は、単に「土地がある」「建物が建つ」より前に決まりやすく、ここで遅れると後工程が全部ずれます。
投資家として重要なのは、ここが工期遅延ではなく、稼働開始の前提条件になっている点です。つまり、設備・施工が順調でも、受電が確定しないとMWが立ち上がりません。
- 「系統連系(接続)の確定」「受電開始(送電開始)」という表現の有無
- 計画発表→着工→竣工の時系列が、受電条件と整合しているか
- 同一エリアに案件が集中していないか(受電点の奪い合いが起きやすい)
ボトルネック②:変電設備(変圧器・開閉装置・配電盤)
次に詰まるのが、変電設備の調達と納期です。
AI DCのMWが増えるほど、変圧器・開閉装置・受配電盤・保護リレーなどの需要が増えますが、これらは「代替が効きにくい」「仕様が重い」「リードタイムが伸びやすい」という性質があります。
ここで投資家が狙いやすいのは、「AIの勝者を当てる」よりも、MWが増える限り需要が落ちにくい装置群に注目することです。MW競争の世界では、設備が間に合わないが最も現実的な遅延要因になりやすいからです。
ボトルネック③:冷却
AI DCは、電気を入れれば入れるほど熱が出ます。結局、熱を捨てられないとMWを増やせません。
さらに日本では、政策的にも省エネ(高効率)を求める方向が明確です。経済産業省の取りまとめでは、2029年度以降の新設データセンターは稼働2年後にPUE 1.3以下とする方向性が示されています。

PUE(Power Usage Effectiveness)は、データセンターのエネルギー効率を表す代表指標で、定義はシンプルです。
一般的な解説でも同様で、「データセンターに入る総電力」を「IT機器に使われる電力」で割る比率、PUEが1.0に近いほど効率が高いと説明されます。
より具体的に説明すると、
つまり、PUEを下げる=同じIT負荷(MW)を動かすのに、必要な総受電や無駄が減る、ということです。
この「PUE規律」は、株の世界ではかなり強い意味を持ちます。なぜなら、PUEを下げるには、
- 電源変換効率(損失を減らす)
- 配電損失(銅損、変換段数)を減らす
- 冷却の方式を高度化する(液冷など)
といった、効率に効く投資が削りにくいからです。
MWが増える局面ほど、冷却と電力効率は「コスト」ではなく「稼働の条件」になっていきます。
PUE 1.3が投資配分を変える?MW競争は「効率投資」を強制する
MW競争を「電力が足りる/足りない」だけで語ると、銘柄まで落ちません。
株に直結するのは、増設局面で 何にお金が落ちるかです。そして、その配分を強制的に変える規律が PUE です。
 ナスダックくん
ナスダックくんこれをみなさんは知りたいのだ?
先ほど提示したように、経済産業省の取りまとめでは、2029年度以降に新設されるデータセンターは、稼働2年後にPUE 1.3以下とする方向性が示されています。
ここで言いたいのは、「2029年以降の話だから関係ない」ではありません。規律が決まると、現場は先に動きます。特にAI DCは、高密度化で熱と損失が増えるので、効率投資を後回しにすると、そもそもMWが積めないからです。
PUE 1.3とは「IT 1に対して施設全体1.3」
PUEは「データセンター全体の消費エネルギー」を「IT機器(サーバ等)の消費エネルギー」で割った指標。
PUE=1.3なら、ITに1使うために施設全体で1.3使います。差分の0.3は、主に以下に消えます。
- 冷却(チラー、ポンプ、ファン等)
- 電源変換損失(AC/DC、DC/DC、UPS等)
- 配電損失(銅損、変圧、開閉、配電経路)
- その他(照明、補機等)
この差分は「無駄」と言い切れません。AI DCは熱が出るので冷却は不可欠です。ただし、規律としてPUE 1.3が求められると、同じMWを動かすのに必要な設備の質が上がり、投資の優先順位が変わります。
PUE規律が生む「投資の3つの偏り」
PUE 1.3は、投資配分を次の3方向に寄せます。ここが銘柄発掘に落とし込めるポイントです。
偏り①:冷却は「増設のたびに必ず必要」です
AIラックの高密度化が進むほど、空冷だけでの最適化は難しくなります。すると液冷(ダイレクト液冷)や、熱交換の高度化、冷却系統の冗長構成など、冷却がコストではなく稼働条件になります。
つまり、MWが増える局面ほど冷却投資が増えやすく、ここは比較的「需要が読みやすい」領域です。
偏り②:電源変換の損失は「削りやすい無駄」なので狙われます
PUE改善で効くところは、冷却だけではありません。電源変換の損失(熱)を減らすことは、PUEにも発熱にも同時に効きます。
ここが後で、ローム(6963)×NVIDIAの論点(800V DC)や、SiC/GaNの必然性につながります。電源変換でロスが出るほど、熱として冷却側に跳ね返り、二重に効率を悪化させるからです。
偏り③:配電・アーキテクチャは「根本から変える」動機になります
PUE 1.3という規律が効いてくると、「設備を良くする」だけでは足りなくなり、配電方式や電圧体系の変更が合理的になります。
たとえば、従来の48Vや12V中心の世界では、大電流化による損失や配線の制約が問題になります。そこで高電圧DC給電(例:800V DC)の発想が出てきます。
ローム(6963)は、NVIDIAと次世代AIデータセンター向け800V電力供給アーキテクチャの開発で協業すると発表しています。
さらにロームのホワイトペーパーでは、従来の48V/12V方式が限界に近づき、800V DCではSiC/GaNが不可欠といった方向性が述べられています。
ここで重要なのは、協業そのものを材料視することではありません。
PUE規律と高密度化が進むほど、電源変換・配電損失・発熱を同時に最適化する必要があり、その解として高電圧DCや新しい電源アーキテクチャが現実味を帯びる、という構造です。
投資家の結論:「効率投資」は削れない
PUE 1.3の世界では、効率に効く投資が「努力目標」から「稼働条件」に近づきます。
この結果、MW競争の勝者は単にGPUを確保した企業ではなく、次の条件を満たせるプレイヤーになります。
- 受電枠を確保し、設備を間に合わせられる
- 冷却・配電・電源を高効率に設計できる
- 規律に沿った運用(PUEの維持)を続けられる
そして株の世界では、こうした勝者より先に、勝者が必ず買うもの(冷却・配電・高効率電源)を押さえるほうが、確率が高い局面が多いです。
AI対応データセンターのIT供給電力が2026年末に約600MWへ倍増、PUE = 1.3 を目的とした動きを簡単にシミュレーションしてみます。
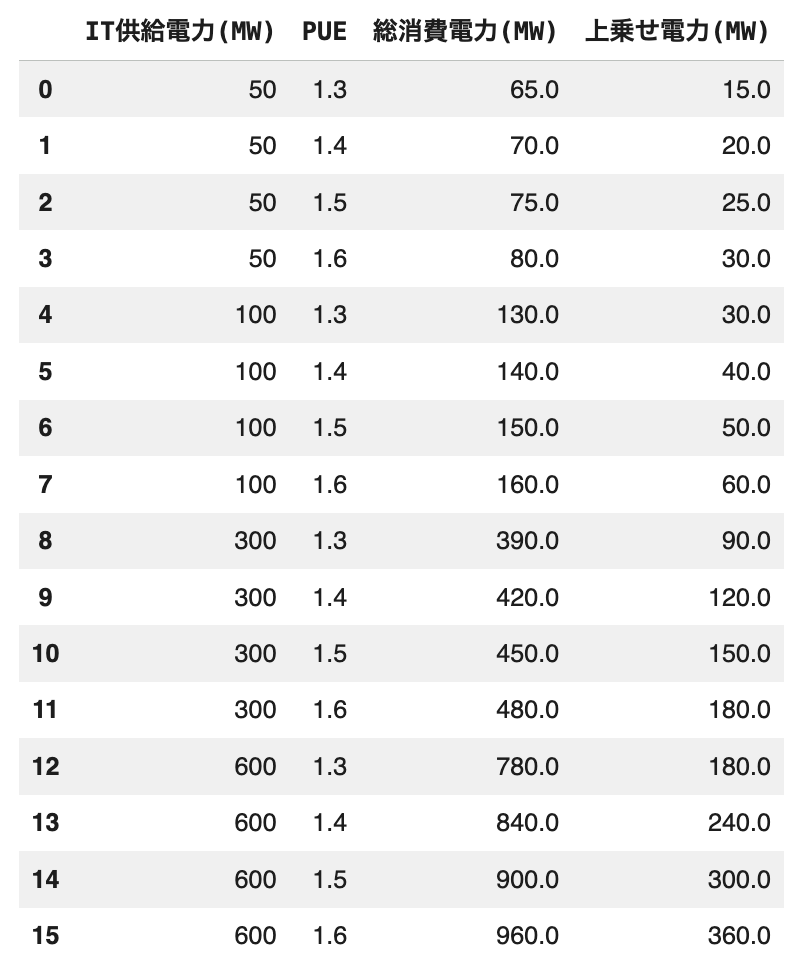
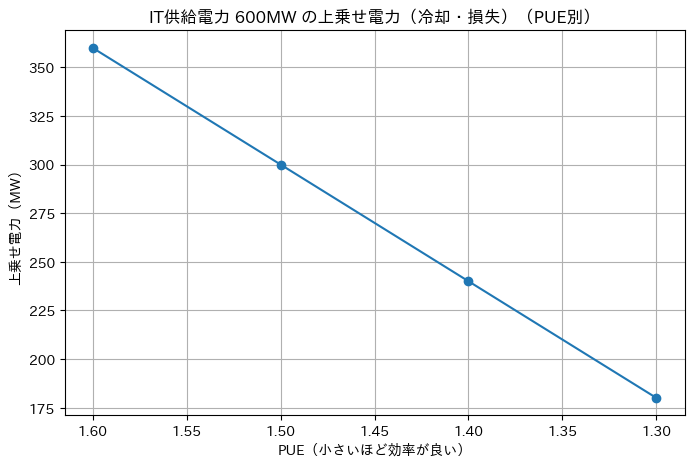
上図のように仮データを作成して、PUEの数値ごとの変異を見てみると、
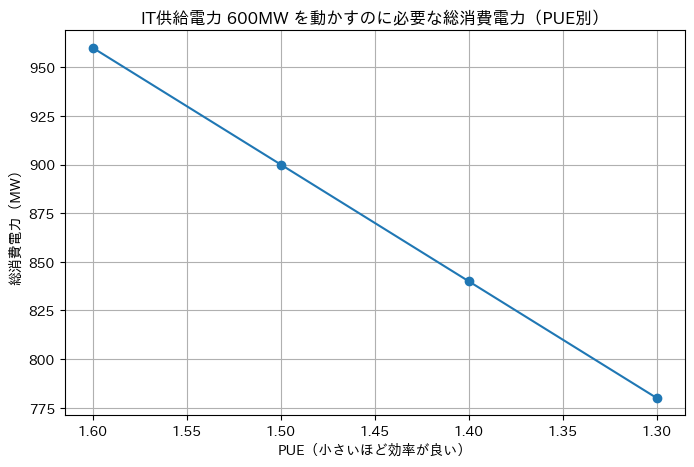
PUEが良くなるほど、同じIT供給電力でも必要な総電力が減る
→ 電力制約(受電枠・系統接続)のハードルが下がります
PUEが良くなるほど、上乗せ電力(冷却や損失)が減る
→ ムダが減り、熱も減り、結果的にさらに運用しやすくなります
このようになります。
つまり、AIデータセンターが増えるほど、事業者は「MWを積み上げる」ために
- 冷却を高度化する
- 電源変換の損失を減らす
- 配電のやり方を変える(高電圧DCなど)
といった 効率投資を避けにくくなります。
つまり、PUE規律の世界では、効率改善に直結する設備・部材・半導体にお金が落ちやすい、という読みになります。
電源アーキテクチャが変わる:48Vの延長ではAIラックが回らない(800V DCという現実)
すで述べた通り、PUE 1.3の規律は「冷却を頑張る」だけでは達成しにくく、電源変換の損失(=熱)と配電損失を減らす方向へ投資を押し出します。ここで登場するのが、AIデータセンターの電源アーキテクチャの転換です。
何が起きているのか:電力が増えるほど損失が雪だるまになる
AIラックの消費電力が上がると、単純に必要な電力(MW)が増えるだけではありません。問題は、電源の世界では
- 変換段数が多いほど損失が増える
- 大電流ほど配線・バスバーの損失が増える
- 損失は熱になり、冷却側の負荷になる
という「二重の悪化」が起きる点です。つまり、損失が増えるほどPUEが悪化し、PUEが悪化するほど冷却が増え、さらに損失が増えるという構造になりやすいです。
このため、高密度AIでは「48Vを太くする」だけでは限界が見えてきます。ここがMW競争の中核です。建物ができても、電気を効率よくラックに届けられなければMWが積めません。
800V DCは材料ではなく、損失と熱の方程式を変える試み
ロームは、NVIDIAと次世代AIデータセンター向けの800V電力供給アーキテクチャの開発で協業すると発表しています。
さらにロームのホワイトペーパーでは、従来の48V/12Vの延長が限界に近づき、800V DCへの移行でSiC/GaNが不可欠といった方向性が示されています。
ここで投資家が押さえるべきポイントは、「800Vが流行るか」ではありません。
次の2つが、株の論点になります。
- 電源変換の損失を減らすことが、PUEと冷却の両方に効く
- 配電方式の変更は、一度決まるとサプライチェーンが固定化しやすい
つまり、800V DCは新しい規格のネタではなく、MWを積み上げるための必然として出てきている、という位置づけです。
800V DCで何が変わるのか → 投資先が「電源ラック」へ寄る
ざっくり言うと、800V DCの方向性は「データセンター内のどこで、どの電圧に変換するか」を再設計する話です。これにより、投資が次のように動きます。
- 電源変換(AC→DC、DC→DC)の場所が変わる
→ PSU(電源)の構成、冗長設計、保護設計の考え方が変わります - 配電機器(バスバー、PDU、遮断器、コネクタ)の仕様が変わる
→ 高電圧DCに対応した設計・安全規格・部材が必要になります - 発熱が減れば冷却側の設計も変わる
→ 冷却投資が不要になるわけではありませんが、「熱を減らす」方向の改善は強力です
ここまで来ると、SiC/GaNの話は単なる「省エネ半導体」ではなく、高電圧・高効率の電源変換を成立させるための部品として位置づきが変わります。
電圧が上がると電流が減ります(電流が減るというよりは、減らしても同様のパワーを出せるという意味)。供給電力を600kWで仮定してみてみましょう。
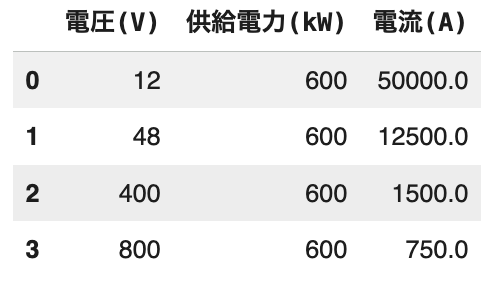
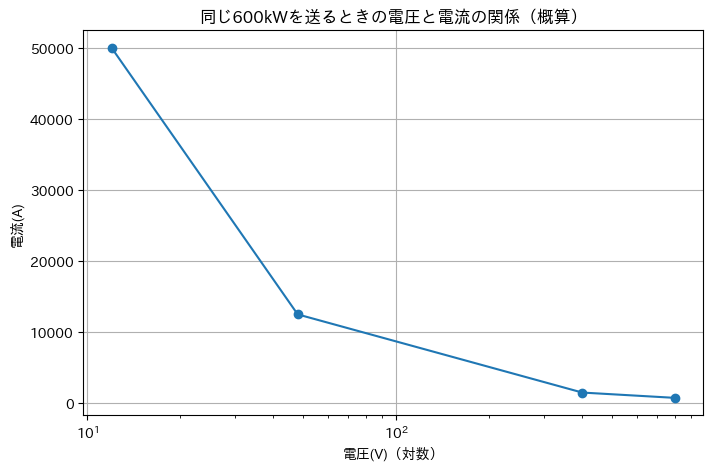
つまり、同じ電力を送るなら「電圧を上げると電流は下がります」。
水道で例えると、
- 電圧=水圧
- 電流=水の流量
- 電力=運べる仕事量(どれだけの水車を回せるか)
同じ仕事量(電力)を運ぶなら、
- 水圧(電圧)を高くできれば
- 流量(電流)を少なくしても同じ仕事ができます
だから「高電圧で送る」のは、太い水流(大電流)を流さずに済むというメリットがあります。
ここで、「同じ600kWを送る」前提のまま、48Vと800Vで配線損失(I²R)がどれだけ違うかを、仮の抵抗Rを置いて図にしてみました。
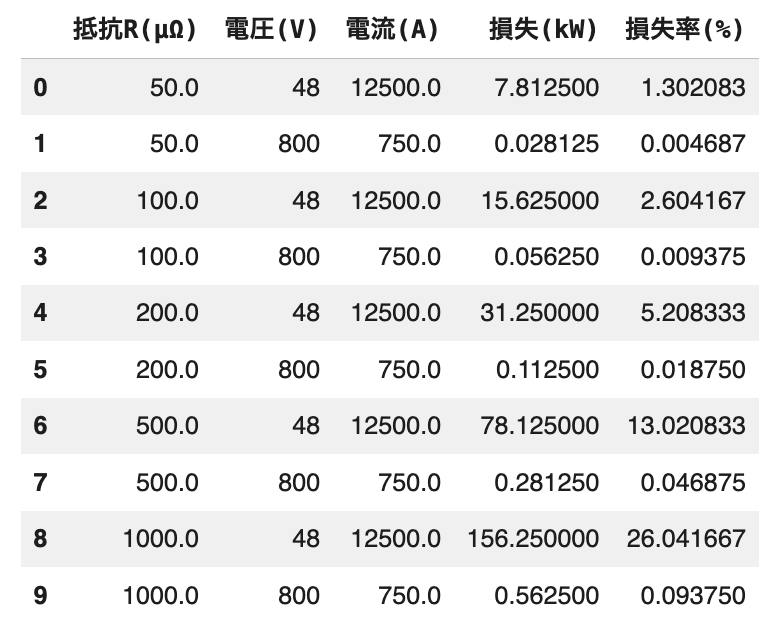
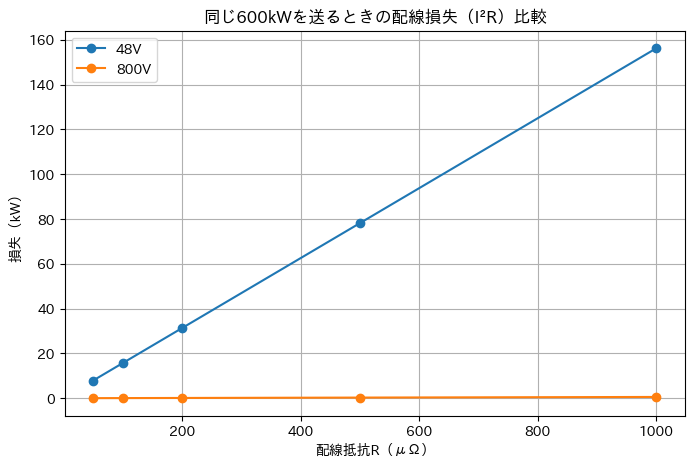
かなり簡易的な例ですが、
- 損失は I²R(電流の2乗×抵抗)で増えます。
- 同じ電力を送るなら I(電流) = P(電力) / V (電圧)なので、電圧Vを上げると電流Iは下がります。
- 電流が下がると I² が効いて、損失は一気に小さくなります。
- 48V→800Vは電圧が約16.7倍なので、電流は1/16.7になります。
- すると I²は(1/16.7)² ≈ 1/278 になり、配線損失が大幅に減ります。
- 損失は熱になるので、損失が減るほど冷却負荷も減り、PUE改善にも寄与しやすくなります。
こんなイメージです!
ここでSiC/GaN関連銘柄を整理し直すと投資判断が変わる
株探系の記事ではSiC/GaN/ダイヤ関連が一緒に語られがちです。
しかし、MW競争の観点では、「すぐにお金が落ちる層」と「遠い将来のオプション」が混ざると判断が鈍ります。ここは工程で分けます。
- 近い層(DC増設の現場に近い):電源変換・配電・冷却に直結するデバイス/モジュール/部材
- 中間層:量産に入るまで時間はかかるが、規格移行が進めば伸びる
- 遠い層(オプション):研究・実証段階が長く、テーマ先行になりやすい(例:ダイヤ系)
この整理をした上で、ロームの協業は「材料ニュース」ではなく、近い層への設計標準の布石として読み替えられます。
SiC/GaN銘柄は「工程との距離」で整理:テーマ株の連想をやめて、MW競争に直結する順に並べ替える
ここまでで整理した通り、国内AIデータセンターのMW競争は「建物」ではなく、受電・変電・配電・冷却・電源変換効率で詰まりやすくなります。
そしてPUE 1.3の規律は、冷却だけでなく電源変換損失(=熱)と配電損失の削減を強制します。
この文脈に置き直すと、SiCやGaNは「省エネ半導体の夢」ではなく、高効率の電源変換を成立させてMWを積むための部品になります。
一方で、株探系の記事はSiC/GaN/ダイヤ関連をひとまとめにしやすく、銘柄リストが連想ゲームになりがち。
投資家としては、ここを「工程との距離」で整理し直すのが筋です。距離が近いほど、MWが積み上がる局面で需要が発生しやすく、遠いほどオプションになります。
銘柄分類:近い/中間/遠い
分類をしていきましょう。
近い(MWが立ち上がるほど需要が出やすい)
「配電・電源変換・設備投資」に直結する領域。
データセンター事業者や電源メーカーが投資せざるを得ない領域なので、テーマの当たり外れよりも「MW増設そのもの」に依存しやすいです。
- 高効率電源(AC/DC、DC/DC、UPS周辺)
- 高電圧DC対応の配電・保護(PDU、遮断、コネクタ等)
- 電源変換損失を下げるパワー半導体(SiC/GaNの使われ方がここ)
この層は、ロームがNVIDIAと協業している800V DCの議論とも直結します。
「高電圧DCで損失と熱を減らす」という設計思想が、ここに投資を集めます。
中間(需要は大きいが、量産・採用に時間差が出やすい)
プロセス・装置・材料の層で、採用が決まると強い一方、量産のタイミングが読みにくい領域です。
MW競争の恩恵を受ける可能性は高いのですが、株価の反応は「採用の確度」が見えた時に強く出やすいです。
- GaN加工・製造装置(エッチングなど)
- 研磨・基板・周辺材料
- SiCウエハ関連の評価・検査
遠い:研究・実証が長く、テーマ先行になりやすい
ダイヤモンド半導体などは、性能の夢は大きい一方で、量産・コスト・サプライチェーン確立までの時間が長いことが多い領域です。
この層は「当たれば大きい」ですが、MW競争の短中期とは時間軸がズレやすいので、ポジション管理(小さく、長く)が必要です。
株探リストを「距離」で並べ替えると、見え方が変わる
ここで、株探に出てくる代表例を、ここでは距離で再配置して見ます。
中間〜近い:SiC/GaNの量産・装置に寄る銘柄群
- トレックス・セミコンダクター(6616):SiCパワー半導体の開発(突入/サージ耐性)
- 新電元工業(6844):京セラのSiC事業承継
- サムコ(3436):GaN加工向けの精密エッチング装置
- ノリタケ(5331):GaNウエハ用研磨パッド
- マイポックス(5381):8インチSiCウエハ評価対応(可視化装置)
- 旭化成(3407):GaN関連の研究成果(基板・耐圧等の論点)
ここでの注意点は、これらが「良い/悪い」ではありません。
MW増設のどのタイミングで売上に繋がるかが違うという点が投資判断に効きます。
遠い(オプション):ダイヤモンド半導体関連
- 住石ホールディングス、ジェイテックコーポレーション、住友電気工業、冨士ダイス、タカトリ、イーディーピー等
この層は、短期のMW競争の材料としては距離があるため、ここでは「夢」を煽らず、オプションとして扱うくらいに留めておきます。
HBMの次「HBF」は何がどうなるのか:結論はHBMの代替ではなく「推論のメモリ階層を作り替える話」
少し話が変わりますが、HBMの話は、AI投資の文脈でほぼ定番になりました。
一方で「HBMの次はHBFだ」という話は、言葉だけが先行しやすく、結局なにがどう変わって、株はどこを買えばいいのかが整理されていません。ここを、データセンター側の制約から逆算します。
HBFの定義:NANDで「HBM級の帯域」を狙う発想
HBF(High Bandwidth Flash)は、Sandiskが提唱している概念で、ざっくり言えば 「NAND(フラッシュ)をHBM的に扱える形にして、帯域の壁(メモリウォール)を越える」という方向性です。HBFは新しいNANDの形であり、AI推論(inference)で問題になるメモリ帯域と容量のギャップを狙っています。
NAND(ナンド)は、SSDやスマホのストレージに使われるフラッシュメモリの一種です。特徴は次の通りです。
- 電源を切ってもデータが残ります(不揮発性)
- 容量を大きく、比較的安く作れます(1円あたり容量が大きい)
- ただし、読み書きの反応はDRAMより遅いです
- さらに、書き換え回数などの制約があるため、制御(コントローラ)が重要になります
投資の文脈では、NANDは「安く大量に持てる記憶」です。AI推論ではモデルやデータを大量に持つ需要があるので、NANDをより近くに置ければ価値が上がる、という発想がHBFにつながります。
DRAM(ディーラム)は、PCのメモリ(RAM)やサーバの主記憶に使われる揮発性メモリです。
- 電源を切るとデータは消えます(揮発性)
- 反応が速い(レイテンシが小さい)
- 帯域も出しやすい(特にHBMのように積層するとさらに太くなる)
- ただし、同じ容量ならNANDより高価になりやすいです
投資の文脈では、DRAM(特にHBM)は「高価でも速さが必要なところ」に使われます。AIの学習や推論で、GPUが待たされないようにするための中核がDRAM(HBM)です。
重要なのは、HBFが「DRAMであるHBMを置き換える」よりも、むしろ
- 推論で必要なデータ(巨大なモデル/KVキャッシュ等)を、より大容量・低コスト側に寄せたい
- でもSSDのように遠い(遅い)と使えない
- なので、DRAMよりは遅いが、近くて太いNANDを作りたい
というメモリ階層の再設計の話になっている点です。
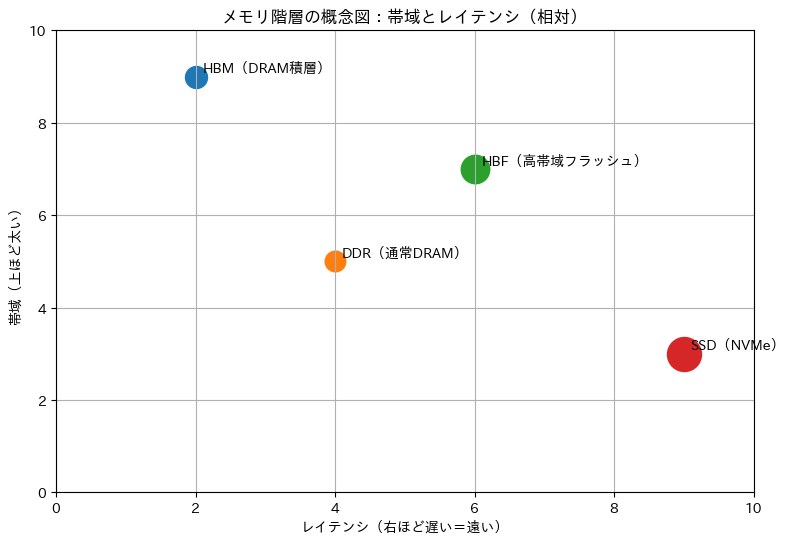
帯域(bandwidth)は、超ざっくり言うと「1秒間にどれだけデータを運べるか」です。
水道で言えば「ホースの太さ」に近いです。
- 帯域が太い=たくさん流せる
- 帯域が細い=渋滞して流れない
AI(特にGPU)は計算が速すぎるので、メモリからデータを供給できないと計算が止まって待つ状態になります。これがいわゆる「メモリの壁(メモリボトルネック)」です。
帯域が足りないと起きることはシンプルです。
- GPUが演算できるのに、必要な重みや中間データが届かない
- 結果として、高いGPUを買っても稼働率が下がる(投資効率が悪化する)
投資家目線では、帯域が重要になるほど「HBM」「近いメモリ」「メモリ周辺の実装・検査」の価値が上がりやすくなります。
HBFは「2026年下期サンプル→2027年初の推論デバイスサンプル」想定
SK hynixとHBF仕様の標準化に向けた協業(標準化・技術要件の明確化など)も公表されています。
この時間軸は投資家にとって非常に重要です。理由は単純で、「今すぐの業績ドライバー」ではなく「設計採用・標準化の進捗が株価ドライバーになりやすい」からです。
短中期はHBMが不要になるより「HBMがさらに進化する」が基本線
HBFが出てくるからといって、HBMがすぐ不要になるわけではありません。
むしろHBMも進化が続いていて、HBM4の生産時期として2026年、HBM4Eが2027年頃という見立ても複数出ています(ただしロードマップは企業・記事により幅があります)。

ここでの投資家の整理はこんな感じです。
- 学習(training):超低遅延・超高帯域が必須 → HBMの重要性が高い
- 推論(inference):容量とコスト、電力が効く → HBMだけで全部持つのが苦しくなる
→ ここにHBFの出番が生まれます
つまりHBFは「HBMの次」ではなく、推論の現実に合わせてHBMだけで戦う設計を緩める選択肢として出てきます。
勝ち筋は「メモリメーカー当て」より周辺サプライチェーンになりやすい
HBFは、うまくいけば大きい一方で、標準化・量産・採用の不確実性が残ります。こういう局面で、クオンタメンタル的に「確率の高いところ」から取るなら、見方は2段階です。
(A) 確率が高い:HBMもHBFも避けられない後工程・実装
HBMが進化し続け、HBFが近いNANDを志向するなら、共通して増えるのは
- 積層・接合(ボンディング)
- 封止・アンダーフィル等の信頼性工程
- 検査(積層が増えるほど歩留まり管理が重要)
です。HBM4でも接合やパッケージングの難しさが議論になっており、製造・実装はボトルネックになりやすいです。
ここは「メモリ規格がどれが勝つか」と独立に需要が立ちやすい領域です。
(B) 不確実だが大きい:HBFが本格化するとフラッシュの作り方と載せ方が変わる
SandiskはHBFでウェハボンディング等を含む独自技術を前提に語っています。
ここが進むと、NAND側の設備投資や材料投資、そして周辺の実装投資が新しい形で増える可能性があります。ただし、ここは標準化・採用が進むかどうかが分岐点です。
まとめ:結局どこにお金が落ちるのか
ここまでの結論を、投資家の意思決定に使える形にまとめます。
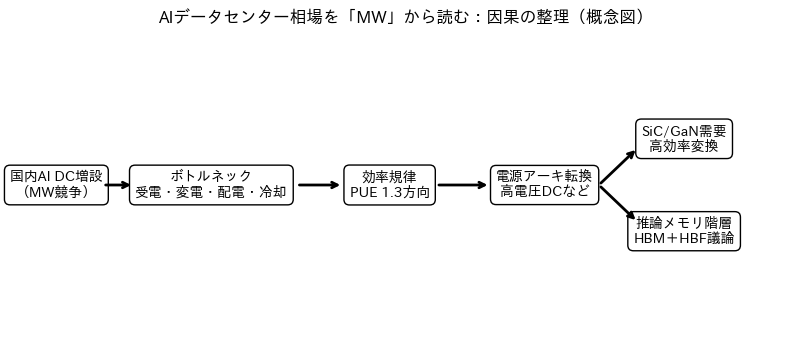
ポイントは、AIデータセンター相場を「GPUの強さ」ではなく、MW(IT供給電力)を積み上げるための制約から読むことです。国内ではAI対応データセンターのIT供給電力が2026年末に約600MWへ倍増する見通しが示されていますが、道中は受電・設備・冷却・効率で計画と実現がズレやすい構造です。
大局の因果はこれ
本稿で固定した因果は、次の一本線です。
- 国内AI DCが増える → MW(IT供給電力)を積む競争になります
- MWを積むには、建物ではなく 受電・変電・配電・冷却が詰まりやすいです
- さらに政策として PUE 1.3が規律になる方向が示され、効率投資が避けにくくなります。(meti.go.jp)
- 効率投資は「冷却」だけでなく「電源変換損失」や「配電損失」を狙うため、電源アーキテクチャの変更(例:高電圧DC)が現実味を帯びます
- その結果、SiC/GaNは“テーマ”ではなく、MWを積むための高効率電源部品として需要が出やすくなります
- さらに推論側では、HBMだけでは苦しくなる場面が増え、HBFのような中間のメモリ階層が議論されます(ただし時間軸は2026年以降の採用フェーズ)。
この因果の強みは、「当て物」になりにくい点です。MWが増えるなら必ず必要になる投資を先に取れます。
投資家向け監視リスト
ここからが、マネーチャットの次の勉強会予定の実務部分。銘柄名を断言するより、観測点(KPI)を置いて、ニュースに振り回されない形にします。
- データセンター側(需給の観測点)
- 国内AI DCの「稼働開始」のニュースが増えているか(計画→実現の進み具合)
- 受電・変電設備の納期が改善しているか/悪化しているか
- PUEや液冷に関する記載が「定性→定量」へ変わっているか
- 電源アーキ側(採用の観測点)
- 「48V限界」「高電圧DC」「電源ラック」などの言葉が、誰の資料に出始めるか
- 協業→評価採用→量産採用へと文言が変化するか
- 電源メーカー(PSU/電源ラック)との関係が明示されるか
- メモリ階層側(HBFの観測点)
- 2026年下期のサンプル提供が実際に進むか(時間軸の確認)(sandisk.com)
- 標準化(仕様策定)が進んでいるか(業界連携の広がり)
- 「推論の実装で何が詰まっているか」の説明が具体化するか
AIデータセンター相場は、派手な材料(GPU、提携、次世代メモリ)ほど注目されます。しかし投資家が最初に押さえるべきは、地味で硬い制約です。MWを積めるか、そしてそのMWを効率良く回せるか。ここに、設備・部材・半導体の需要が集まります。
マネーチャットでは、この「観測点チェックリスト」をベースに、各社IRの読み方と、ボトルネック投資の見極めを継続していきます。
マネーチャットでは、超初心者から中級者の方にぴったりな投資の学校を運営しています。毎週の動画学習に加え、毎日の経済解説、そしてみんなと一緒に学習したり意見交換したりする場を作っています。
とりあえず無料で1ヶ月やってみよう! =>
https://community.camp-fire.jp/projects/view/760550#menu










